What Insurance Process Automation Actually Fixes in 2026

I have a slightly unpopular opinion for 2026: most insurance process automation programs fail because they are trying to sound impressive instead of fixing the work that quietly drains margin every day.
The biggest gains are usually not hiding in some futuristic boardroom slide. They are sitting in the shared inbox, the spreadsheet nobody trusts, the loss run PDF with sideways pages, the claim photo that may or may not be real, and the poor underwriter who has become a highly paid copy-paste machine.
After a decade around insurance operations, underwriting, and claims teams, I’ve learned to get suspicious when someone says they want to automate the department. That is too broad. Too grand. Too likely to become a 14-month steering committee with nice snacks and no production workflow.
The better question is simpler: what work should never have needed a human in the first place?
That is where insurance process automation earns its keep in 2026. It fixes repeatable handoffs, admin drag, data quality gaps, triage delays, and visibility problems. It does not replace judgment. It clears the fog so judgment can show up before the broker, claimant, or regulator starts tapping their foot.
The real enemy is handoff drag
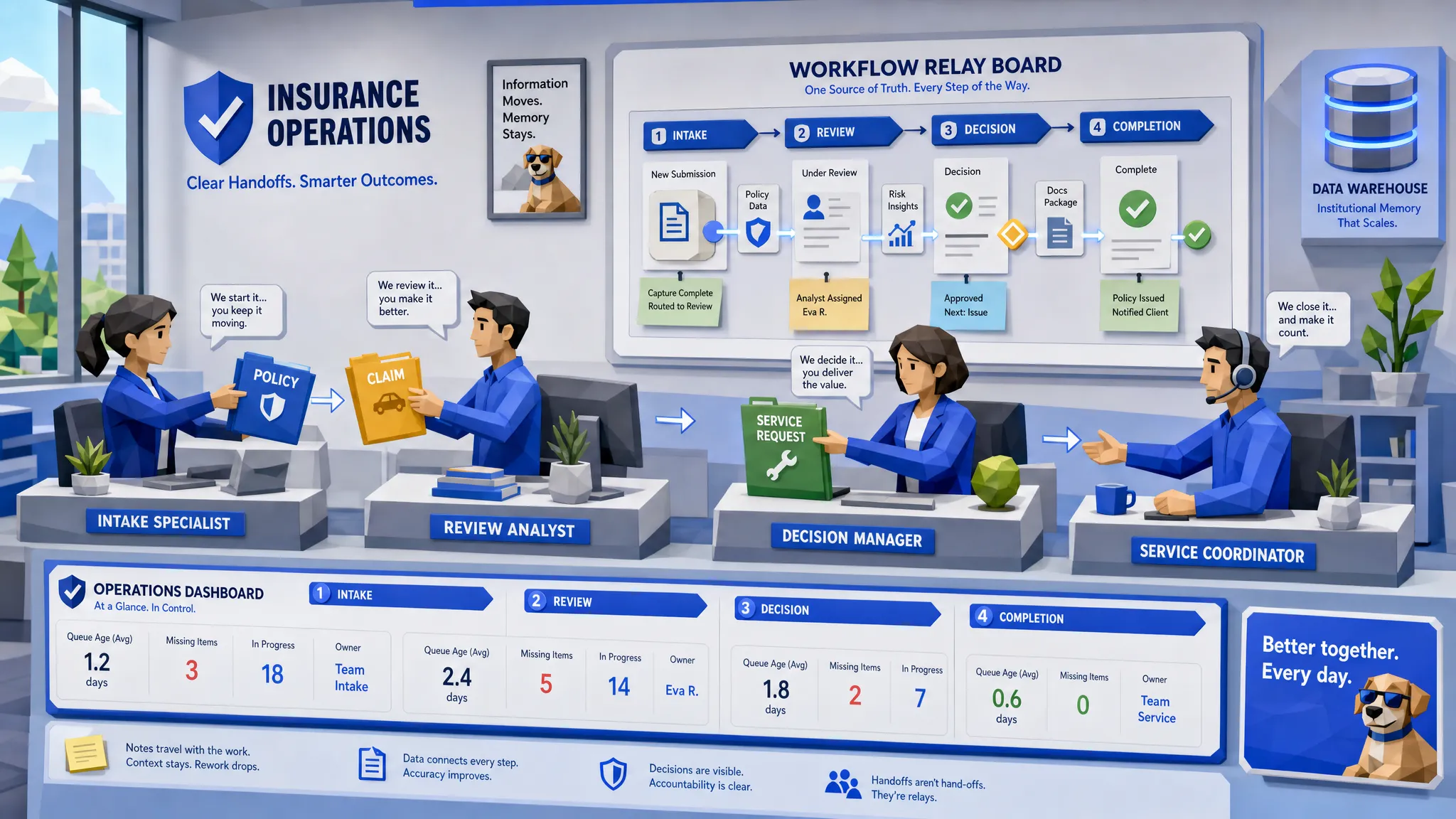
Every insurance team has its own version of handoff drag. A broker emails a submission. Someone downloads attachments. Someone renames files. Someone checks whether the VIN is valid, whether the driver list matches the fleet schedule, whether prior coverage is real, whether the loss run dates make sense, and whether the quote system agrees with the spreadsheet.
Then, after all that, an underwriter finally gets to think about risk. If they are lucky.
I once watched a senior underwriter spend an entire morning comparing two fleet schedules because the same driver appeared under three slightly different names. This was a person who could price commercial auto risk with the calm confidence of a chess player. Yet there they were, hunting for duplicate rows like a detective in a very boring crime drama.
That is the problem. The risk did not need four hours. The process did.
McKinsey has reported that underwriters can spend around 60% of their time on administrative work rather than risk assessment. In my experience, that statistic feels painfully believable. If anything, some days it feels polite.
Insurance process automation fixes this by moving intake, validation, enrichment, routing, and reporting into controlled workflows. That means the human expert sees the file when the file is ready for expertise, not when it is still a pile of unverified fragments.
What insurance process automation actually fixes
Underwriting admin that steals risk time
The first thing automation fixes is the pre-underwriting mess. That includes submission intake, document classification, data extraction, field validation, third-party enrichment, eligibility checks, quote preparation, and referral routing.
For an MGA, this can mean turning broker submissions, ACORD forms, loss runs, fleet schedules, and emails into structured data before an underwriter touches the account. For a carrier, it can mean enforcing rules consistently across channels instead of trusting each team to remember the latest underwriting bulletin. For brokers, it can mean faster quote turnaround because the submission does not disappear into a black hole of manual review.
The key phrase here is structured data. If your process ends with a cleaner PDF sitting in another folder, you have improved document handling. Useful, yes. Transformative, not quite. The real fix is getting the right data into the right system with the right validation at the right time.
Think about a physical supply chain. A distributor handling truckloads and bulk pallets for sale would not treat every carton as a brand-new mystery. They standardize intake, labeling, routing, and shipment because otherwise the warehouse becomes chaos with forklifts. Insurance has its own warehouse problem, except the pallets are PDFs, emails, photos, invoices, claims notes, and quote files.
Automation gives those items a place to go and a rule for what happens next.
The copy-paste tax across systems
Insurance has a re-keying problem, and we all know it. Data moves from email to spreadsheet, spreadsheet to policy admin system, policy admin system to claims system, claims system to reporting pack, and then someone asks why the numbers do not match.
This is not just annoying. It creates underwriting leakage, claim delays, compliance exposure, and management reports that arrive late enough to qualify as historical fiction.
Insurance process automation reduces this copy-paste tax by connecting workflows to existing systems and capturing the data once. That matters because manual entry errors are rarely dramatic. They are small. A transposed VIN. A missed exclusion. A wrong effective date. A discount applied after eligibility changed. A claim reserve copied from an old version of the file.
Small errors do not stay small when they scale across a book of business.
The fix is not to ask staff to be more careful. Good people already try to be careful. The fix is to make the process less dependent on perfect human repetition.
Claims triage before a small claim becomes an angry claim
Claims automation gets plenty of attention, but I think the most valuable part is not the dramatic instant settlement use case. The real value is earlier triage.
When FNOL is slow or incomplete, everything downstream gets worse. Coverage checks take longer. Adjuster assignment becomes reactive. Fraud signals arrive late. Claimants call for updates. Litigation risk creeps upward. The file becomes noisy before anyone has really assessed it.
J.D. Power’s 2024 U.S. Auto Claims Satisfaction Study highlighted the ongoing pain around auto claim cycle times, with many claims taking more than 30 days to settle. Meanwhile, Celent has found that only about 10% to 15% of claims are processed straight-through without human intervention.
That gap is the opportunity.
Automation can collect FNOL data, read documents, classify claim type, check coverage, analyze images, flag missing information, route urgent files, and keep the claimant informed. The adjuster still handles judgment-heavy issues, but they are not wasting the first stretch of the claim trying to find the basics.
A claims manager once told me her team did triage by inbox archaeology. I laughed because it was funny. Then I stopped laughing because it was accurate.
Fraud triage in a world of synthetic evidence
Fraud has become faster, cheaper, and more digital. That is a grim sentence, but it is where we are.
The FBI estimates that insurance fraud costs the United States more than $300 billion per year. On the claims side, the problem is getting more complicated because fraudsters now have better tools for creating fake documents, staged photos, synthetic identities, and inflated invoices.
Verisk’s 2025 fraud report found that carriers are increasingly concerned about AI-enabled digital fraud, including fabricated or manipulated evidence. If your fraud workflow still depends mainly on manual review and static rules, you are asking people to spot digital tricks at conveyor-belt speed. That is not a fair fight.
Here is my hot take: fraud automation is only useful if it improves triage. If it creates 500 low-quality alerts, it is just an expensive panic button.
Good automation looks across the file. It can compare submitted images with metadata, check invoice patterns, identify repeated vendors, flag inconsistencies between FNOL details and damage photos, and connect claims signals to underwriting data. It should separate suspicious from merely unusual, because unusual customers still deserve decent service.
The best outcome is not catching every bad actor with a flashing red warning. The best outcome is giving fraud analysts fewer, better, earlier signals.
Customer service work that should not require a human queue
Customers do not care how complex your internal systems are. I say that with love, because our internal systems are often very complex.
A policyholder asking whether their document was received should not wait two days. A broker asking for quote status should not need to chase three people. A claimant asking what happens next should not feel like they are sending a message into a canyon.
Insurance process automation can handle status updates, document requests, routine coverage questions, proof-of-prior follow-ups, payment reminders, and routing. The trick is knowing when not to automate. Sensitive conversations, complex coverage disputes, injury claims, complaints, and escalations still need human care.
In 2026, the winning service model is not full automation. It is clean automation with smart handoffs. The customer gets speed when the answer is straightforward and a human when the moment calls for judgment.
That may sound obvious. Oddly, obvious things are often the most under-implemented.
Management visibility that arrives before the quarter ends
This is the part executives should care about more than they usually do.
If your automation only moves tasks faster, you gain speed. If it also captures the data behind every step, you gain visibility. Those are very different levels of value.
A workflow should tell you which submissions are missing data, which brokers send clean files, which claim types stall, which adjusters are overloaded, which eligibility checks create the most referrals, and where premium leakage is appearing. That record of what happened is what turns automation from a productivity project into a business intelligence engine.
This is especially important for MGAs and carriers managing portfolios across distribution partners, geographies, and product lines. Faster processing is helpful. Knowing why one book is drifting from expected loss behavior is strategic.
What automation does not fix
Now for the part vendors sometimes whisper and operators usually know: automation will not rescue a broken decision framework.
If your underwriting appetite is unclear, automation will expose that. If every exception requires three informal approvals, automation will expose that. If your data definitions vary by department, automation will expose that. If nobody owns the workflow after go-live, automation will expose that too.
That is not a reason to avoid automation. It is a reason to start with a process you can define.
A good first workflow has clear inputs, repeatable decisions, measurable outcomes, and known exception paths. If the team needs 15 committee meetings just to define what good looks like, park it for later. Pick something with friction you can see and ROI you can measure.
The best candidates usually have high volume, frequent re-keying, obvious validation rules, measurable cycle time, and a clean path to human review. That could be loss run extraction, FNOL intake, proof-of-prior verification, attorney demand triage, invoice review, fleet schedule validation, broker email routing, or endorsement processing.
Start where automation can remove work without removing accountability.
Why 2026 is different
Three things have changed.
First, the operational pressure is higher. Expense ratios matter. Talent is stretched. Experienced underwriters and adjusters are too valuable to spend their days cleaning data.
Second, customer expectations are less forgiving. People track food delivery in real time. They expect the same basic transparency from a claim or policy request. Fair or not, that is the benchmark now.
Third, the fraud environment is moving faster. Synthetic documents, manipulated images, and digitally coordinated fraud rings are harder to catch with manual controls alone.
That is why so many insurance leaders are investing. Accenture has reported that a large share of insurance CEOs are investing in AI for areas such as claims and underwriting. The motivation is not trend-chasing. It is survival math.
But 2026 also demands more discipline. Insurers do not need another endless proof of concept. They need production workflows, governance, reporting, and integration into the systems teams already use.
How Inaza approaches the problem
At Inaza, we think insurance process automation should do three practical things: reduce manual work, improve data quality, and create visibility across the business.
The platform is designed for insurers, MGAs, brokers, reinsurers, underwriters, claims adjusters, fraud analysts, and operations teams that need automation without ripping out their existing systems. It supports automation across underwriting, claims, customer service, and operations, with customizable workflows, support for all file types, and more than 250 workflow templates.
The part I like most is that workflow automation is only the starting point. Inaza has a unified data warehouse underneath it, so the data captured through automation can feed reporting, analytics, and dashboards. That means leaders can see where processes are working, where they are leaking, and how performance compares over time.
Inaza also includes pre-built API templates for enrichment sources such as Verisk, LexisNexis, HazardHub, and more, which helps teams avoid rebuilding the same integrations repeatedly. Industry benchmarks, including references from firms such as Aon, Munich Re, and Howden, can also help teams compare portfolio performance and support clearer narratives for renewals or reinsurance discussions.
And perhaps most importantly for operators tired of PoC theater, Inaza is built to help teams deploy production-ready workflows quickly, including from a single working session when the use case is defined. That matters because the goal is not to admire automation in a sandbox. The goal is to fix the work.
Frequently Asked Questions
What is insurance process automation? Insurance process automation is the use of software workflows to handle repeatable insurance tasks such as data intake, validation, routing, document processing, claims triage, fraud checks, customer communication, and reporting. The goal is to reduce manual admin while keeping human oversight where judgment is needed.
Which insurance processes should be automated first in 2026? Start with high-volume processes that involve repetitive data handling, clear rules, and measurable delays. Common starting points include FNOL intake, loss run extraction, fleet schedule validation, proof-of-prior checks, broker email triage, claims document review, and routine customer service requests.
Does automation replace underwriters and adjusters? No, not when it is done properly. Automation should remove low-value admin, surface better data, and route exceptions to the right person. Underwriters and adjusters still make judgment calls on complex risks, coverage questions, negotiations, and sensitive claims.
How does insurance process automation help reduce fraud? Automation helps by checking data earlier and more consistently. It can flag suspicious claim photos, inconsistent FNOL details, unusual invoice patterns, repeated vendor behavior, missing metadata, and other signals that are hard to catch manually at scale.
How should insurers measure automation ROI? Track cycle time, touchpoints per file, manual hours saved, error rates, quote-to-bind speed, claim settlement time, fraud referral quality, customer satisfaction, leakage reduction, and staff capacity. The best metric depends on the workflow, but every automation project should have a measurable business outcome before it starts.
Ready to fix the work behind the work?
If your team is still moving submissions, claims, emails, and documents through manual handoffs, the problem probably is not effort. Insurance people work plenty hard. The problem is that too much of the process still depends on humans doing machine-shaped tasks.
Inaza helps insurers, MGAs, and brokers automate underwriting, claims, customer service, and operations while integrating with existing systems. If you want to move from manual bottlenecks to measurable workflows, we can help you identify the right first process and get it into production without the usual back-and-forth.