The Insurance Underwriting Process Has an Intake Problem
I’ll give you my hot take right up front: most underwriting teams do not have a risk assessment problem first. They have an intake problem.
That sounds less exciting than talking about pricing sophistication, predictive models, or the next big data source. But after a decade around insurance operations, I’ve seen the same movie too many times. A carrier invests in better underwriting logic, only for submissions to keep arriving as a half-complete ACORD, three PDFs, two spreadsheet tabs, a broker email that says “see attached,” and a loss run named final_v7_REALLYFINAL.xlsx.
By the time the underwriter finally sees the risk clearly, the broker has already chased two other markets.
The insurance underwriting process is supposed to be a disciplined path from submission to quote to bind. In practice, the front door is often a junk drawer. And no amount of underwriting genius fixes a junk drawer if your best people spend their mornings sorting it.
The real bottleneck in the insurance underwriting process
On paper, the insurance underwriting process looks clean. A submission comes in. The insurer checks appetite. Data is gathered and verified. The risk is evaluated. Terms are prepared. The quote goes out. If everyone likes what they see, the policy binds.
Lovely. Very tidy. Also, not how Tuesday usually goes.
Real underwriting starts with messy intake. Submissions arrive across email, portals, shared drives, broker platforms, PDF attachments, scanned documents, spreadsheets, photos, and sometimes, my personal favorite, a “quick note” in the body of an email that contains the most important exposure detail in the entire submission.
I once saw a commercial auto submission where the vehicle count appeared three different ways: 42 in the email, 39 in the ACORD, and 44 in the spreadsheet. Nobody was trying to be difficult. The broker was moving fast, the insured had updated the fleet, and the underwriter was left playing detective with a calculator and a strong coffee.
That is not underwriting. That is clerical archaeology.
McKinsey has noted that underwriters can spend up to 60% of their time on administrative work rather than core risk assessment. That tracks with what I’ve seen. The biggest leak in underwriting productivity often happens before the underwriter makes a single risk decision.

What I mean by “intake problem”
An intake problem is not simply “we get too many submissions.” That is the nice problem. The real issue is that submissions arrive in inconsistent, incomplete, and unstructured formats, then require manual work before they can be evaluated.
Bad intake shows up in familiar ways:
- Underwriters re-keying data from PDFs into policy or rating systems.
- Assistants chasing missing driver lists, prior loss details, roof updates, payroll splits, or entity names.
- Brokers sending duplicate versions because nobody has acknowledged receipt quickly enough.
- Appetite checks happening late because the right data was buried in an attachment.
- Referrals triggered by missing or contradictory information rather than actual risk complexity.
- Managers lacking reliable visibility into why submissions stall.
The frustrating part is that every carrier and MGA knows this is happening. We have built rituals around it: “submission clearance,” “desk review,” “triage,” “pending info,” “follow-up queue.” Those are useful controls, but they often mask the same underlying issue. Intake is not producing clean, usable underwriting data fast enough.
If underwriting is a kitchen, intake is food prep. You can hire a brilliant chef, but if every ingredient arrives unlabeled in a grocery bag, dinner will be late.
Portals helped, but they did not solve the problem
Here is another unpopular opinion: the industry slightly overestimated portals.
Portals are useful. They can standardize questions, reduce missing fields, and guide brokers through required documents. But a portal-first strategy can quietly become a polite way of telling brokers to do your intake department’s job.
That may work for some simple risks. It breaks down when a broker is submitting a complex commercial account to several markets, each with its own portal, appetite questions, document requirements, and quirks. If your portal takes 35 minutes and your competitor accepts the broker’s email package, guess who gets the first shot?
In 2026, the best intake strategy is not forcing every submission into one perfect channel. It is meeting the market where the market already works, then turning whatever arrives into structured data behind the scenes.
That means accepting emails, attachments, ACORD forms, PDFs, spreadsheets, images, loss runs, and supplemental forms without making the underwriter or broker clean everything manually first.
Bad intake causes more than slow quotes
Slow quote turnaround gets most of the attention, and rightly so. In broker-distributed business, speed matters. But intake problems create several quieter costs that are just as damaging.
First, they increase premium leakage. If driver details, vehicle attributes, payroll classifications, property characteristics, prior losses, or discount eligibility are missed or keyed incorrectly, pricing can drift away from actual risk. One small field rarely sinks a book. Thousands of small field errors add up.
Second, poor intake weakens risk selection. Underwriters make better calls when they see a complete picture early. If the loss run is processed late, or an external data check is run after the quote is already half-built, the team is working with a foggy windshield.
Third, bad intake hurts broker relationships. Brokers do not mind thoughtful questions. They do mind being asked for the same document twice, or hearing nothing for four days, then receiving a last-minute request for information that was attached in the original email. I have been on those calls. Nobody leaves feeling like a strategic partner.
Finally, messy intake damages operational intelligence. If your intake data is trapped in inboxes and documents, leadership cannot reliably answer basic questions: Which brokers send the cleanest submissions? Which lines stall most often? Which data fields cause the most rework? Which appetite rules are creating unnecessary referrals?
Without that visibility, management ends up running underwriting operations by anecdote. Anecdotes are useful over lunch. They are less useful when setting capacity plans.
What good underwriting intake should look like
Good intake should feel almost boring. That is a compliment.
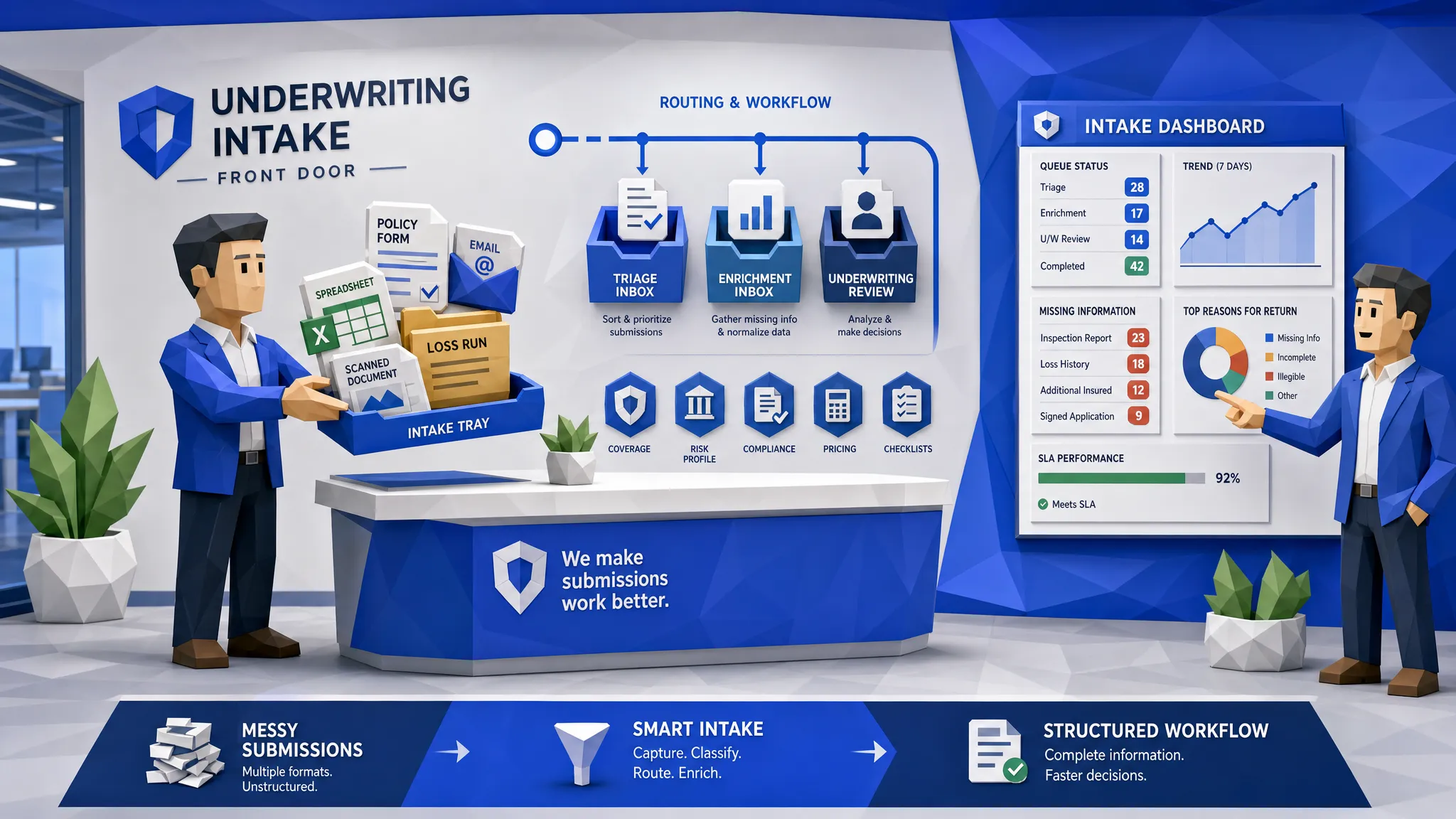
A strong intake workflow captures incoming submissions, classifies the documents, extracts the relevant data, checks it against underwriting requirements, enriches it where needed, and routes it to the right person or system. The underwriter should receive a clean view of the risk, with gaps and exceptions clearly flagged.
In practical terms, that means the workflow should answer a few questions before the underwriter loses half the morning:
- What type of submission is this?
- Is it new business, renewal, endorsement, or a quote update?
- Which documents arrived, and which are missing?
- Do key fields conflict across the email, ACORD, spreadsheet, and loss run?
- Does the risk appear to fit appetite?
- Which external checks should be run automatically?
- Who should handle it next?
- What happened at every step for audit and reporting?
Notice that none of this removes underwriting judgment. It protects it. The underwriter should be spending time on risk quality, terms, pricing judgment, portfolio fit, and broker negotiation. They should not be squinting at a scanned supplemental form wondering whether that number is a 3 or an 8.
The best intake automation starts small, then compounds
I get nervous when an insurer says, “We want to transform the entire underwriting process in one go.” I admire the ambition. I also admire bridges that are built one solid section at a time.
The smarter move is to begin with a high-friction intake workflow. Commercial auto fleet schedules. Loss run extraction. ACORD form intake. Broker email triage. Proof-of-prior checks. Property data enrichment. Pick the area where the pain is visible, the volume is meaningful, and the business case is not theoretical.
Then measure what happens. How much re-keying disappears? How much faster do submissions reach an underwriter? How many incomplete submissions are flagged immediately? How many referrals are truly risk-based versus data-quality noise?
That last question matters. I have seen teams celebrate referral discipline when half the referrals were really intake failures wearing a blazer.
Adoption also deserves more attention than it usually gets. If underwriters do not understand where extracted data came from, why a submission was routed, or how to override a workflow safely, they will go back to email and spreadsheets. Product and operations teams working through those adoption traps can borrow useful patterns from the AI Product Adoption Deck, especially around trust gaps and the moments where users stop relying on a tool.
Insurance teams do not adopt automation because a vendor says it is clever. They adopt it because it saves time, explains itself, and does not make them look foolish in front of a broker.
Why data enrichment belongs at intake, not after the quote is half-built
Many carriers and MGAs treat enrichment as a later step. A submission gets reviewed, some data gets keyed, then someone runs third-party checks. That sequencing is backwards for many workflows.
If the intake layer can enrich data early, the underwriter gets a better starting point. Driver history, property hazard information, vehicle data, business attributes, loss history, court or public record checks, and other external signals can help determine appetite and routing before the submission lands in the wrong queue.
This is where pre-built API templates matter. If an intake workflow can connect with sources like Verisk, LexisNexis, HazardHub, and other data providers without a custom build every time, insurers can enrich submissions faster and more consistently.
The point is not to overwhelm underwriters with more data. We already have plenty of that. The point is to bring the right data into the workflow at the moment it changes the next action.
That distinction sounds small, but operationally, it is huge.
The intake layer should feed your data warehouse
Here is where I get a little nerdy, but only a little.
Every intake workflow creates valuable operational data. Submission source. Broker. document type. Missing fields. Clearance status. Appetite outcome. Referral reason. Time in queue. Enrichment results. Underwriter override. Quote outcome. Bind outcome.
If those data points are captured in a unified data warehouse, underwriting leaders can move from gut feel to actual management insight. They can see which brokers submit profitable, complete business. They can identify friction by line of business. They can track cycle time and accuracy. They can compare internal performance against benchmarks and build stronger portfolio narratives for renewals, capacity conversations, and reinsurance negotiations.
This is one reason I like intake automation tied to analytics rather than isolated document processing. Document extraction alone is useful. Intake data connected to workflow and reporting is much more valuable.
For a deeper look at why connected data matters across underwriting, Inaza has written about how insurers can understand insurance risk better with a connected-data platform.
How Inaza thinks about the intake problem
At Inaza, we see underwriting intake as the first place automation should prove itself. If the front door is cleaner, everything downstream works better: underwriting, policy issuance, reporting, broker communication, and even claims later in the lifecycle.
Inaza’s platform is built to help insurers, MGAs, and brokers automate data capture, workflow routing, enrichment, reporting, and analytics across existing systems. The goal is not to make teams rip out everything they already use. The goal is to let them deploy useful workflows quickly, often without the long proof-of-concept loop that slows so many insurance technology projects.
A few capabilities matter especially for intake:
- Support for all file types, so teams can handle the documents brokers actually send.
- Customizable workflows, so automation follows underwriting appetite and authority rules.
- More than 250 workflow templates, giving teams a faster starting point.
- Pre-built API templates for enrichment sources such as Verisk, LexisNexis, HazardHub, and others.
- A unified data warehouse, so intake activity turns into reporting and business intelligence.
- Real-time analytics dashboards, including the ability to compare performance against built-in industry benchmarks.
- Integration with existing systems, so teams do not need to retrain everyone around a brand-new operating model.
The practical outcome is simple: get clean submission data into the right workflow faster, then give underwriters better context for the decisions only they should make.
The future of underwriting belongs to the teams that fix the front door
The winners in underwriting will not only be the companies with the most sophisticated pricing models. They will be the companies that can receive messy market information, make sense of it quickly, enrich it intelligently, and respond before the opportunity goes cold.
That starts with intake.
I know intake is not the glamorous part of the insurance underwriting process. Nobody puts “reduced attachment chaos” on a conference keynote slide and expects a standing ovation. But in the real world, the unglamorous bottleneck is often where the money is.
Fix intake, and underwriters get time back. Brokers get faster answers. Operations leaders get visibility. Data teams get cleaner inputs. Executives get a more accurate view of the book.
And maybe, just maybe, we can finally retire the spreadsheet named final_v7_REALLYFINAL.xlsx.
Frequently Asked Questions
What is intake in the insurance underwriting process? Intake is the stage where submissions, documents, emails, forms, and supporting data first enter the underwriting workflow. It includes capturing, classifying, validating, enriching, and routing information before the underwriter evaluates the risk.
Why do underwriting submissions get delayed? Submissions are often delayed because information arrives incomplete, inconsistent, or spread across multiple files and channels. Underwriters or assistants then have to manually re-key data, chase missing documents, resolve conflicts, and run external checks before risk assessment can begin.
Can underwriting intake be automated without replacing core systems? Yes. Modern intake automation can sit around existing policy, rating, CRM, and document systems. The key is integration, configurable workflows, and support for the file types and submission channels your brokers already use.
Does automating intake replace underwriters? No. Automating intake reduces clerical work so underwriters can focus on judgment, risk selection, pricing decisions, broker negotiation, and portfolio strategy. The best systems keep humans in control of complex decisions.
How does better intake improve broker relationships? Better intake gives brokers faster acknowledgements, clearer follow-ups, fewer duplicate requests, and quicker quote decisions. That makes it easier for brokers to place business with your team, especially in competitive lines.
Ready to fix underwriting intake?
If your underwriting team is spending too much time cleaning submissions before they can evaluate risk, the process is already costing you speed, capacity, and broker goodwill.
Inaza helps insurers, MGAs, and brokers automate underwriting intake, enrich submissions, connect workflows, and turn operational data into useful analytics. If you want cleaner inputs and faster decisions without a painful system replacement, it may be time to fix the front door first.