How to Improve P&C Insurance Combined Ratio With Better Data

If your combined ratio is under pressure, the fastest path to improvement is usually not a new pricing plan or another headcount request. It is better data, applied consistently across underwriting and claims.
In P&C, the insurance combined ratio is ultimately the sum of two things you can influence every day:
- Loss ratio (how accurately you select and price risk, and how much “premium leakage” you allow)
- Expense ratio (how efficiently you acquire, underwrite, and service business)
Then, because claims is where most dollars actually leave the building, data also determines how well you control claim severity, fraud, and legal/attorney demand costs.
What the insurance combined ratio really measures
The insurance combined ratio is commonly expressed as:
Combined ratio = loss ratio + expense ratio
A ratio below 100 generally indicates an underwriting profit (before investment income). Above 100 indicates you are paying out more in losses and expenses than you are bringing in via premium.
The important takeaway is that combined ratio is not a single “finance metric.” It is the scoreboard for operational execution across the policy lifecycle.
Why “better data” moves combined ratio more than most initiatives
Most combined ratio improvement programs fail for a simple reason: they try to change decisions without changing inputs.
In P&C, decisions are only as good as the data feeding:
- Submission intake and validation
- Pricing and eligibility checks
- Claims triage and reserving
- Fraud detection and claim handling
- Legal demand response and negotiation
When data is incomplete, inconsistent, or trapped in PDFs, emails, or siloed systems, you get predictable outcomes:
- Mispriced risk and adverse selection
- Premium leakage from missed surcharges, incorrect attributes, or rating inputs that never make it to the system of record
- Operational bottlenecks that inflate expense ratio
- Slower, more expensive claims with higher LAE, more leakage, and more litigation friction
The goal is not “more data.” It is usable data: structured, validated, enriched, and available where the workflow happens.

1) Improve loss ratio by underwriting more accurately (and stopping premium leakage)
Loss ratio improvement starts before you bind. Better data helps you avoid two costly patterns:
- Adverse selection (accepting risks you did not intend to write, or writing them at the wrong price)
- Premium leakage (writing the risk, but failing to collect the premium you should have charged)
Underwriting accuracy: reduce misclassification and “silent” risk drift
In many P&C workflows, the underwriter is forced to make decisions with partial information:
- Missing or mismatched vehicle, driver, location, or exposure attributes
- Inconsistent answers across documents (applications vs supplements vs loss runs)
- Unverified self-reported data
- Prior loss details locked in unstructured formats
Better data changes underwriting in two practical ways:
Real-time validation at intake. Instead of discovering problems after the quote is built, you catch them as the submission is ingested. That reduces rework, speeds turnaround, and eliminates “decisioning on bad inputs.”
Enrichment before rating and binding. Pre-bind enrichment (via third-party sources or internal systems) improves risk segmentation without adding manual steps. The key is that enrichment is automatic, repeatable, and auditable.
If you want a deeper look at why this matters operationally, Inaza has a related perspective in Underwriting Without Good Data Is Just Guessing.
Premium leakage: better data protects the denominator
Loss ratio is often discussed as a claims problem, but premium quality is just as important. Leakage happens when underwriting teams miss details that should impact price, eligibility, or coverage.
Common leakage drivers include:
- Attributes that never get keyed (or get keyed inconsistently)
- Discounts applied without evidence
- Mismatched exposures across documents
- Endorsements processed late, or not rated correctly
Better data reduces leakage by making sure the underwriting file is:
- Complete (required fields are present)
- Consistent (cross-field checks confirm the story matches)
- Verified (supporting evidence exists for discounts and classifications)
Inaza has an auto-focused leakage example here: Premium Leakage in Auto Insurance: How to Catch What Your Underwriters Miss.
What “better underwriting data” looks like in practice
For carriers and MGAs, the biggest wins tend to come from workflow-level improvements rather than one-off reporting projects:
- AI extraction from PDFs, emails, and attachments so submissions and loss runs become structured data (not just stored documents)
- Field-level QA (format checks, outlier detection, cross-document consistency)
- API-based enrichment to pull in external signals when needed
- Closed-loop feedback from claims to underwriting so your risk rules and models learn from real outcomes
Inaza’s approach is designed around these realities: production-ready workflows you can deploy quickly, plus a unified data warehouse underneath the automation so improved underwriting decisions also become measurable.
2) Improve expense ratio by writing more business with the same team
Expense ratio is where many organizations feel trapped: hiring is expensive, training is slow, and new business volume is volatile.
Better data improves expense ratio because it enables straight-through work (or at least “low-touch” work) across underwriting and servicing.
The hidden expense ratio driver: manual handling caused by messy data
A surprisingly large portion of underwriting and operations cost is not “underwriting judgment.” It is:
- Re-keying data from documents into systems
- Chasing missing fields
- Fixing inconsistent records
- Reworking the same file across multiple teams
When the data is structured and validated at the edge (inbox, portal, upload, API), your team spends more time on true exceptions.
That is how you get the outcome that actually moves the expense ratio:
more policies processed per underwriter/adjuster, without lowering decision quality.
For more context on reducing operational friction, see Reducing Touchpoints with STP.
Better data enables scalable workflows (not just faster tasks)
To improve expense ratio sustainably, automation has to be repeatable across lines, states, and edge cases. Data is what makes that possible.
Look for automation that:
- Supports all file types (because your partners and insureds will not standardize overnight)
- Integrates with existing systems (core, PAS, claims, CRM, data tools)
- Does not require retraining the whole team to get value
- Captures key operational events as data, so you can measure throughput, rework, and cycle time
Inaza’s platform is built for workflow deployment without prolonged proof-of-concept cycles, and for capturing structured data points from each automation to power dashboards and reporting.
3) Reduce cost of claims with data that catches fraud and shortens time-to-resolution
Claims cost is not just indemnity. It is also LAE, leakage, and the compounding cost of slow decisions.
Better data reduces the cost of claims in three high-impact ways that directly support combined ratio improvement.
Catch more fraud (and catch it earlier)
Fraud is partly a detection problem, but it is also a data standardization problem.
Fraud signals often exist, but are hard to connect:
- Reused photos or suspicious documentation
- Repeating entities across claims (addresses, phones, repair facilities)
- Invoices that do not match the claimed damage or normal patterns
- Timing anomalies around policy inception, endorsements, or coverage changes
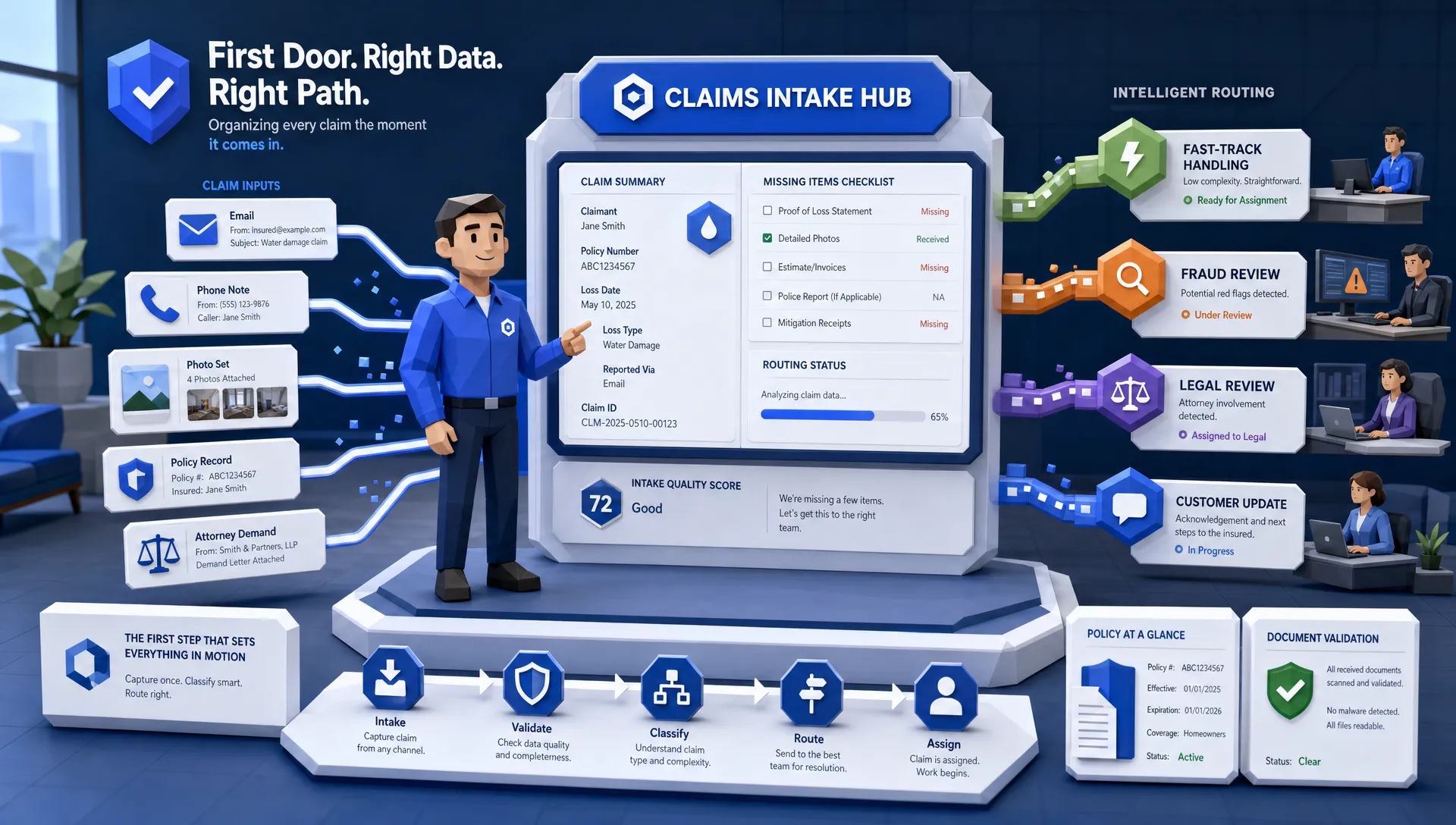
When claims intake data is unstructured, fraud tools cannot reliably score it. When it is structured and enriched, you can:
- Auto-triage claims to SIU review vs fast-track
- Run anomaly detection consistently
- Reduce the number of low-value manual reviews that consume adjuster time
Related reading from Inaza includes Building a Fraud-Resistant Claims Workflow and Stopping Internet-Sourced Photo Fraud.
Respond to attorney demands quickly (and reduce legal friction)
Attorney demands and litigation workflows are where delays become expensive. The cost is not only legal spend, it is also:
- Extended cycle times
- Increased settlement values due to slow response
- Extra handling and document rework
- Poor documentation continuity across systems
Better data helps in two operational ways:
Faster demand package assembly. If you can automatically extract and organize key claim file elements (coverage, correspondence, bills, notes, estimates), you reduce the time spent “finding the file” and increase the time spent making the right decision.
Cleaner, more complete audit trails. Structured claim events and standardized documentation reduce negotiation ambiguity and internal back-and-forth.
Settle small claims quickly without losing control
Fast settlement is not just a CX improvement, it is a combined ratio lever. Small claims often become disproportionately expensive when they require multiple handoffs.
Better data enables:
- Accurate triage at FNOL (fast-track vs complex)
- Automated verification and document collection
- Consistent application of thresholds and rules
- Quicker routing to appraisal, repair networks, or payment workflows
This reduces LAE and keeps adjusters focused on severity.
If you are exploring cycle time reduction broadly, see How AI Reduces Claims Cycle Times by 90% for examples of where automation tends to compress timelines.
Make combined ratio improvement measurable: the data warehouse advantage
A common trap is implementing point automations that save time, but do not improve the combined ratio because no one can prove impact, or replicate success.
To make the improvement durable, you need to capture the data produced by workflows and convert it into decision-ready reporting:
- Quote and bind conversion, including quote abandonment drivers
- Leakage indicators (missing fields, overrides, late endorsements)
- Underwriting cycle time and rework rate
- Claims cycle time by segment and channel
- Fraud hit rate and referral quality (to avoid overwhelming SIU)
- Attorney demand response time and outcomes
Inaza’s model pairs workflow automation with an underlying data warehouse so you can move from automation to analytics without rebuilding your reporting stack. In addition, industry benchmarks built into the system can help teams understand performance versus the market (and support clearer narratives in reinsurance negotiations and renewals).
A practical roadmap: where to start for the biggest combined ratio lift
If your goal is combined ratio improvement (not “AI for AI’s sake”), start where data friction is highest and financial impact is most direct.
Start with underwriting inputs that affect price and eligibility
Focus on intake automation and data QA that prevents:
- Missing exposure details
- Unverified discounts
- Inconsistent data across documents
- Loss history trapped in PDFs
This is the fastest path to loss ratio improvement and premium integrity.
Then scale throughput to improve expense ratio
Once data is clean at the edge, expand automation to reduce manual touches across:
- New business submissions
- Endorsements and policy changes
- Renewal data refresh
- Customer service workflows driven by emails and attachments
Add claims automation where it reduces severity and LAE
Prioritize claims workflows that reduce cost quickly:
- Fraud screening at intake
- Automated invoice/document checks
- Faster claim file organization for attorney demands
- Small-claim fast-track settlement with guardrails
For one claims cost example, see The Hidden Cost of Manual Invoice Reviews.
Frequently Asked Questions
What is a good insurance combined ratio for P&C? Many carriers target a combined ratio below 100 over time, but “good” depends on line of business, growth strategy, and catastrophe exposure.
How does data quality affect loss ratio? Data quality impacts risk selection and pricing. Incomplete or inconsistent underwriting inputs increase mispricing and adverse selection, which shows up as a higher loss ratio.
How does premium leakage impact combined ratio? Premium leakage reduces the premium you collect for the risk you are taking. That can worsen loss ratio and combined ratio even if claims performance does not change.
Can automation really improve expense ratio without hurting underwriting quality? Yes, when automation focuses on data capture, validation, enrichment, and routing. This removes re-keying and rework while keeping true exceptions with underwriters.
How does better data reduce claims costs? Structured, enriched claims data enables faster triage, earlier fraud detection, quicker small-claim settlement, and faster response to attorney demands, all of which reduce LAE and severity.
Turn better data into a better combined ratio
If you are trying to improve your insurance combined ratio, the highest ROI move is usually to fix the data flow that drives underwriting and claims decisions, then measure results in production.
Inaza helps insurers, MGAs, and brokers automate workflows across underwriting and claims while capturing structured data in a unified warehouse for analytics and benchmarks.
Explore the platform at Inaza or reach out to see what a production-ready workflow looks like in your environment.