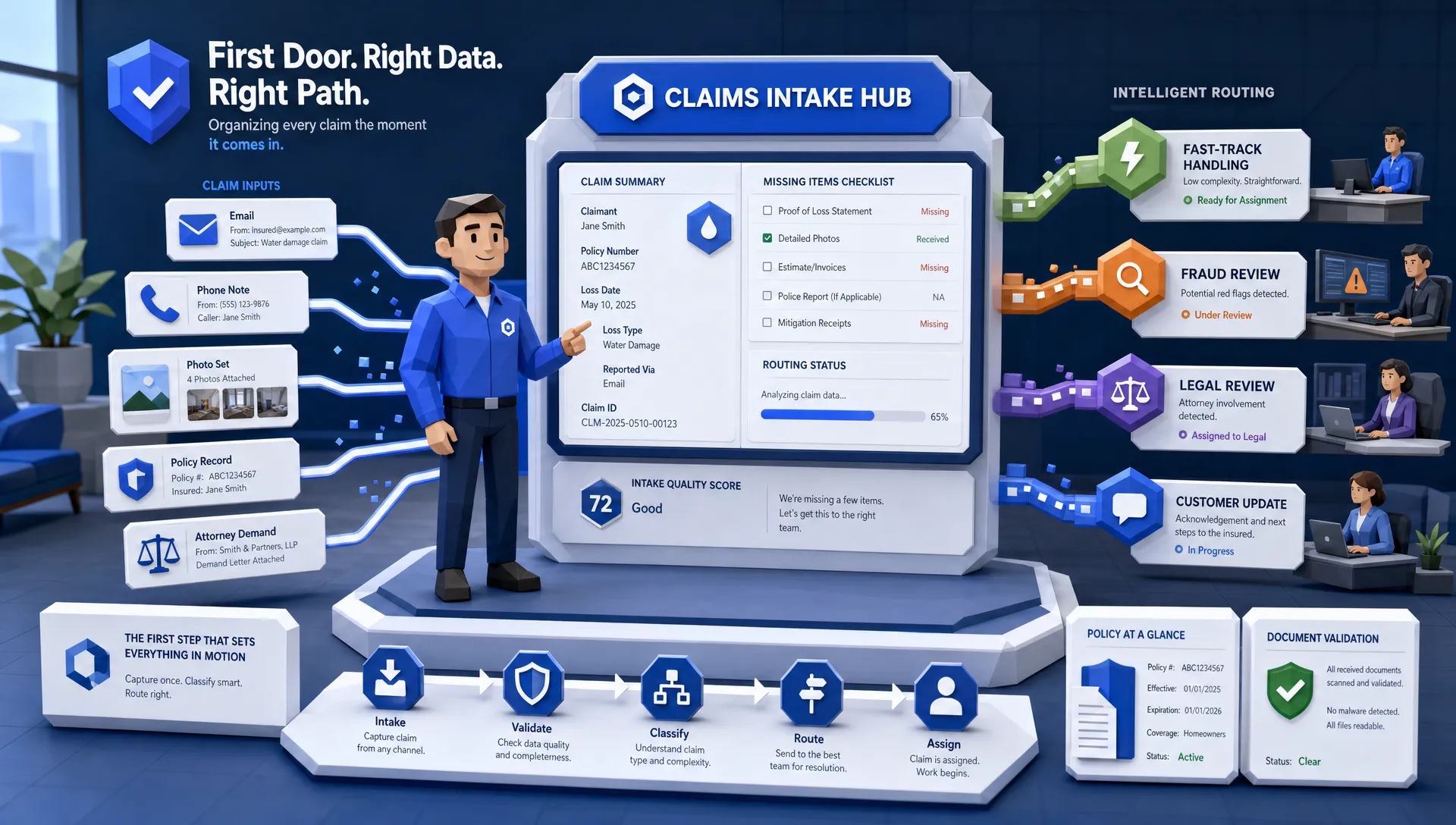
How the Process of Commercial Underwriting Works Today

Commercial underwriting has never been “just rating.” In 2026, the process is still dominated by document collection, verification, and reconciling inconsistencies across submissions, third party data, and internal systems.
That is especially true in commercial auto, general liability (GL), and workers compensation (workers comp), where a single account can arrive with a long list of attachments: five years of loss runs in multiple formats, driver and vehicle schedules, MVRs, payroll and class code details, contracts, certificates, and questionnaires.
When this intake work is manual, the process of underwriting slows down for reasons that have nothing to do with risk judgment. It slows down because the file is messy.
This guide walks through how the process of commercial underwriting works today, focusing on the documents that take the longest to handle consistently and the mistakes that show up most often.

Why commercial underwriting is still document-driven
Even when a broker uses an online portal, the “real” underwriting file typically lives in attachments and follow-up emails. Commercial risks vary widely, so underwriters still rely on supporting documentation to answer four core questions:
- Who (or what) is actually being insured?
- What are the exposures (drivers, vehicles, payroll, operations, locations)?
- What does the loss history say, and is it credible?
- Do the coverages and contractual requirements match what must be insured?
For commercial auto, GL, and workers comp, the problem is not the existence of these questions. The problem is that the answers arrive in formats that are hard to standardize, easy to misread, and time-consuming to validate.
The process of commercial underwriting today (step-by-step)
Underwriting workflows vary by carrier, MGA, and program, but most modern commercial underwriting processes follow the same stages.
1) Submission intake and “What did we receive?” triage
The first stage is not risk selection. It is determining whether the submission is complete enough to work.
Common intake artifacts include:
- ACORD forms and supplemental applications
- Schedules (drivers, vehicles, locations, payroll)
- Loss runs (often 3 to 5 years, sometimes longer)
- Prior carrier documents (dec pages, coverage summaries)
- Industry-specific questionnaires (hazmat, towing, last-mile delivery, contracting)
At this point, many teams informally perform a NIGO check (Not In Good Order): if a key document is missing, the file stalls and becomes a back-and-forth thread.
Where time gets burned:
- Submissions arrive through multiple channels (email, portal upload, shared drive), and attachments are not labeled consistently.
- Key fields are embedded in PDFs or scanned images.
- Multiple versions exist (a “final” driver schedule sent three times).
2) Exposure definition (schedules drive everything)
In commercial lines, schedules are the backbone of the underwriting file. If schedules are incomplete or inconsistent, downstream pricing and eligibility checks become unreliable.
Commercial auto: driver and vehicle schedules
For commercial auto, the driver schedule and vehicle schedule are not “supporting docs.” They are the exposure.
A typical file may include:
- Driver roster (names, DOB, license numbers, hire dates)
- Assigned vehicles or permissive use indicators
- Vehicle list (VIN, year/make/model, radius, garaging ZIP, vehicle type)
- Usage classification (local, intermediate, long haul, business use type)
Common mistakes and failure modes:
- Name matching errors: a driver listed as “Mike” on the schedule and “Michael” on an MVR request can create false mismatches or missed MVR pulls.
- Hidden drivers: seasonal, part-time, or temporary drivers excluded from the schedule, then appearing in loss runs or payroll records.
- VIN issues: transposed digits, missing VINs, or VINs that do not decode to the described vehicle type.
- Garaging vs operating territory mismatch: a schedule states one ZIP, but operational documents imply a different primary territory.
Workers comp: payroll, class codes, and employee schedules
Workers comp underwriting hinges on accurate payroll and classification because pricing is typically tied to exposure bases and job duties.
Underwriters commonly request:
- Payroll by class code (with a breakdown by state)
- Employee counts, job descriptions, and use of subcontractors
- Prior audit outcomes or large changes in payroll
Common mistakes and failure modes:
- Class code drift: job duties evolve, but class codes are not updated.
- State allocation errors: payroll is listed under the “home” state despite multi-state operations.
- Subcontractor confusion: 1099 exposure is treated as excluded without verifying certificates, contracts, or statutory requirements.
For reference on workers comp classification basics, many teams use NCCI’s publicly available resources.
General liability: operations, locations, and contractual obligations
GL underwriting depends heavily on what the insured does and what contracts require.
Documents often include:
- Narrative of operations and revenue streams
- Location schedule, including leased vs owned
- Certificates and additional insured requirements
- Contracts (construction agreements, vendor contracts, transportation broker agreements)
Common mistakes and failure modes:
- Inconsistent descriptions of operations: the ACORD says “contractor,” the website indicates roofing, and the questionnaire indicates subcontracted work.
- Uncaptured contractual risk transfer: the underwriter never receives the contract that drives additional insured and waiver of subrogation requirements.
- Location count mismatches: a schedule includes three locations, but payroll and revenue imply more.
3) Loss history review (where long loss runs dominate cycle time)
Loss runs are the single most time-consuming document set in many commercial underwriting workflows.
A “long loss run” can mean:
- Multiple years (often 5+)
- Multiple prior carriers
- Multiple lines (auto + GL + workers comp) bundled in one PDF packet
- Mixed formats (carrier-generated spreadsheets, scanned PDFs, claim detail reports)
What underwriters need from loss runs is straightforward:
- Frequency, severity, and trend
- Cause of loss patterns
- Open claims and reserve adequacy signals
- Litigation indicators (attorney involvement, subrogation, long-tail development)
What makes long loss runs hard is not the analysis. It is the normalization.
Typical loss run handling steps (manual)
- Locate the latest version and confirm the valuation date.
- Identify the policy periods included (and whether there are gaps).
- Re-key (or copy/paste) losses into an internal worksheet.
- Map carrier-specific claim fields into internal categories.
- Clarify unknowns (e.g., “what does code 17 mean on this carrier’s report?”).
Common mistakes and failure modes:
- Wrong policy period mapping: claims get attributed to the wrong year, which distorts trends.
- Duplicate claims: the same claim appears on two carrier runs and is counted twice.
- Inconsistent cause coding: “rear-end” vs “collision” vs “PD only” becomes an apples-to-oranges comparison.
- Missing large-loss narratives: the headline numbers look acceptable, but the large loss details are buried in adjuster notes or a separate attachment.
If you want a deeper explanation of why PDF formats create this friction, Inaza has a related piece on converting loss runs into structured data: From PDF Chaos to Structured Clarity.
4) Third party checks and enrichment (MVRs are the classic bottleneck)
After exposures and loss history are understood, most teams run eligibility and risk-quality checks using third party data.
For commercial auto, MVR (Motor Vehicle Record) ordering and review is one of the most common sources of delay and inconsistency.
Why MVRs slow things down:
- Requests fail due to small identity mismatches (name formatting, license state, missing DOB).
- Drivers are added late, triggering re-runs.
- Different underwriters interpret similar violations differently unless guidelines are tightly enforced.
- Some workflows involve manual “MVR received” indexing and attaching to the right driver.
Mistakes that show up in practice:
- Wrong driver matched to the wrong MVR (especially with common names).
- Out-of-date MVRs used inadvertently when a renewal file pulls prior-year results.
- Inconsistent violation treatment when rules are applied manually under time pressure.
Commercial underwriting also commonly includes property and location enrichments, business verification, and loss cost signals. For example, many insurers use third party property risk datasets for location-based hazards. One commonly referenced source in the market is HazardHub for property risk intelligence.
5) Pricing, underwriting judgment, and file documentation
Once the file is “clean enough,” the underwriter can focus on pricing and terms.
In practice, pricing is often where earlier document issues surface:
- A driver schedule change alters rating inputs.
- A payroll update changes workers comp premiums.
- A GL operations clarification changes classification and eligibility.
This is where consistent documentation matters. Regulatory expectations vary by jurisdiction and product, but the operational reality is universal: if you cannot reconstruct why a decision was made, audits and referrals become painful.
For general regulatory background on insurance oversight, the NAIC provides state-based regulatory information and model law context.
6) Referral handling, broker questions, and bindable quote delivery
Even when a quote is technically complete, the last mile frequently reintroduces friction:
- Missing required forms (signed applications, exclusions, waivers)
- Contractual evidence for GL (additional insured wording, primary and noncontributory)
- Coverage clarification questions that trigger new documents
This stage can add days simply because the file is being re-assembled, re-reviewed, and re-validated.
Where commercial underwriting time goes (and why consistency breaks)
If you map the end-to-end process, most delays are caused by “document-to-data” work and rework.
The biggest time drivers in commercial auto, GL, and workers comp are typically:
- Long loss runs: extracting, reconciling, and summarizing losses across years and carriers.
- Schedules: driver, vehicle, payroll, and location schedules that arrive as PDFs with multiple revisions.
- MVR workflows: ordering, matching, reviewing, and documenting results.
- Follow-ups: repeated broker outreach to resolve gaps that could have been caught at intake.
Consistency breaks when different people handle the same scenario differently. Common reasons:
- Guidelines exist, but are not embedded into the workflow.
- Underwriters create personal spreadsheets and shortcuts.
- Data is re-keyed into multiple systems, increasing error probability.
The most common (and costly) mistakes by line
Some errors are universal, but each line has repeat offenders.
Commercial auto
- Missing drivers or undisclosed permissive use
- Incorrect vehicle symbols or vehicle type assumptions
- Incorrect garaging, radius, or usage classification
- Duplicate or mis-attributed losses on long loss runs
- MVR mismatches and inconsistent violation treatment
General liability
- Misclassification of operations due to vague narratives
- Missed contractual requirements (additional insured, waivers)
- Understated subcontractor exposure
- Location schedules not aligned with operations reality
Workers comp
- Payroll and class code inconsistencies, especially across states
- Employee schedules not aligned with payroll totals
- Subcontractor treatment without verifying certificates or state requirements
- Prior audit outcomes overlooked (which can signal volatility)
How leading teams make the process faster without lowering underwriting standards
Speed in commercial underwriting does not come from skipping steps. It comes from making the steps repeatable.
Standardize intake around “minimum viable underwriting data”
Most teams know what they need for a first-pass decision, but they do not always enforce it consistently.
A practical approach is to define a minimum intake set for each product (commercial auto, GL, workers comp) and ensure the submission is structured enough to validate before it hits an underwriter’s desk.
Reduce re-keying by structuring documents early
If loss runs, schedules, and MVR results stay trapped in PDFs, underwriters are forced into manual extraction.
When teams convert those documents into structured fields early in the workflow, they can:
- Apply validation rules consistently
- Trigger targeted follow-ups (instead of open-ended “please resend” requests)
- Create summaries that are audit-friendly
Inaza has written specifically about the operational cost of this manual step in Why Manual Loss Run Review Is Costing You.
Validate schedules against each other (cross-document consistency)
Many underwriting errors are not “bad data.” They are inconsistent data.
Examples of cross-checks that reduce mistakes:
- Driver schedule vs loss run named drivers (do new names appear in claims?)
- Payroll totals vs employee counts (do they align directionally?)
- Vehicle schedule vs garaging addresses (do territories align?)
For fleet-heavy submissions, validation is a repeatable win. See: Validating Fleet Submissions with AI.
Instrument the workflow so you can see bottlenecks
If you only measure quote turnaround time, you do not learn where the process breaks. Strong teams track operational causes, such as:
- NIGO rate (and the top missing items)
- Touches per submission (handoffs and rework)
- Average time spent on loss run review
- MVR request failure rate (and reasons)
- Revisions per schedule (driver, vehicle, payroll)
This is where a unified data layer matters, because operational metrics require consistent capture of events and fields.
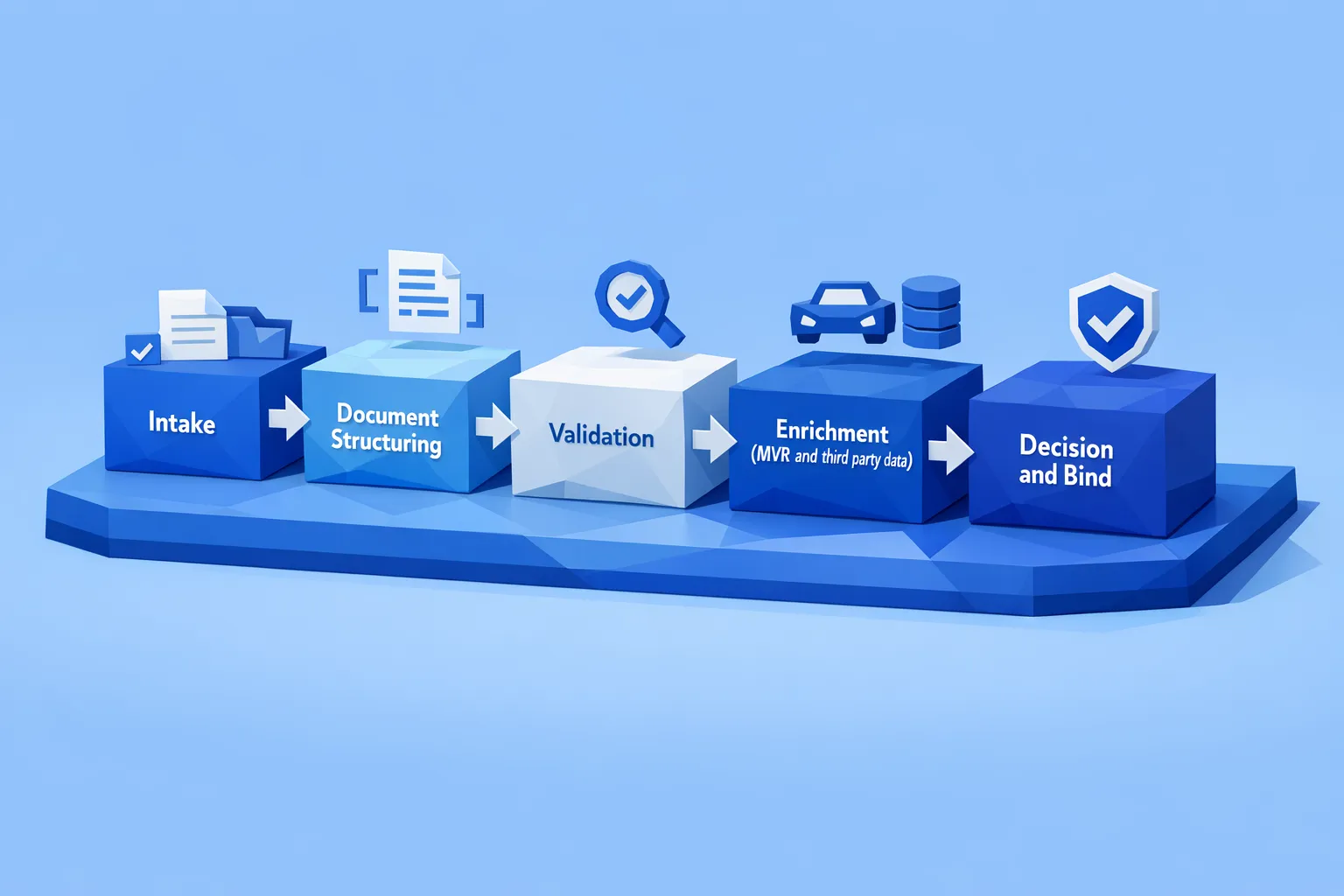
Where automation fits (and where it does not)
Automation is most valuable when it eliminates repetitive work while preserving underwriter oversight.
Good candidates for automation in commercial underwriting include:
- Document classification and data extraction from loss runs and schedules
- Cross-field and cross-document validation rules
- Routing submissions based on completeness and risk flags
- Calling third party data sources through APIs to enrich the file
- Creating consistent summaries for underwriter review
Areas that still benefit from human judgment:
- Interpreting ambiguous operations descriptions
- Negotiating terms and conditions based on portfolio strategy
- Contextualizing loss drivers (one-off vs systemic)
The goal is not “touchless at all costs.” The goal is a workflow where underwriters spend more time underwriting and less time assembling.
Frequently Asked Questions
What is the process of underwriting in commercial insurance? The process of underwriting typically includes submission intake, exposure definition (schedules), loss run review, third party checks like MVRs, pricing and terms, referrals, and binding.
Why do long loss runs slow commercial underwriting so much? Long loss runs often span multiple years and carriers and arrive in inconsistent formats. Time is spent reconciling policy periods, deduplicating claims, and summarizing trends before any pricing decisions can be trusted.
What documents are most important in commercial auto underwriting? Driver schedules, vehicle schedules, and MVRs are foundational. Loss runs are also critical because they reveal claim patterns and open-loss development.
What are common workers comp underwriting mistakes tied to documents? Misclassified payroll, incorrect state allocations, and missing subcontractor documentation (or missing certificates) are common issues that can lead to mispricing and audit friction.
How can carriers and MGAs improve underwriting consistency without slowing down? Standardize intake requirements, structure documents into usable data early, run cross-document validation, and track operational KPIs like NIGO rates and rework to continuously remove bottlenecks.
See how Inaza helps teams handle commercial underwriting documents at scale
If your underwriting team spends more time re-keying loss runs, reconciling schedules, and chasing MVR corrections than evaluating risk, the workflow is telling you where the bottleneck really is.
Inaza provides an AI-powered insurance automation platform that helps insurers, MGAs, and brokers deploy production-ready workflows quickly, integrate with existing systems, and capture structured data in a unified warehouse for reporting and analytics. Inaza also offers pre-built API templates for common insurance data sources, making enrichment easier to operationalize.
Learn more at Inaza or explore the underwriting resources in the Inaza blog to see practical workflow patterns in action.