Data Extraction for Insurance: Turning Unstructured Data into Intelligent Decisions
.png)
Every document your teams touch contains decisions waiting to happen - if only the data were usable. In commercial and specialty insurance, this challenge shows up daily. Broker submissions buried in attachments. FNOLs sent as scanned PDFs. Bordereaux formatted by ten different partners, ten different ways. Legacy loss runs emailed at 5 PM on a Friday. None of it structured. All of it urgent.
And who handles it? Not machines - people. Claims adjusters, underwriting assistants, MGA ops staff, offshore data processors. They read, retype, cross-check, and chase. Hours every day are lost not on analysis or judgement, but simply on finding, formatting, and fixing fragmented data.
Modern insurers have outgrown this. AI-powered data extraction is no longer experimental - it’s essential. The question isn’t whether you need it. It’s whether your platform actually understands the documents you deal with.
Explore the Data Extraction in Insurance Series
This blog is the hub for Inaza’s Data Extraction in Insurance content series — designed for leaders in underwriting, claims, operations, reinsurance, and compliance who are actively tackling the problem of unstructured, inaccessible data across their workflows.
Each article dives into a specific challenge or use case: from real-time extraction to handling legacy data, automating bordereaux, building the right tech stack, and routing structured outputs where they drive value.
Whether you're modernizing your submission intake or cleaning up claims workflows, this series provides the practical insights and technical direction you need.
Explore the full cluster below:
- Data Extraction in Insurance: Turning Unstructured Inputs Into Actionable Insights
- From Emails to Excel: How Insurers Can Extract Data from Any Format
- The Insurance Data Extraction Tech Stack: What You Actually Need
- Real-Time Data Extraction for Underwriting and Claims Teams
- The Problem with Legacy Data: How to Extract and Use It Without a Full Migration
- How MGAs Are Using Intelligent Data Extraction to Speed Up Submission Intake
- Automating the Extraction of Loss Runs, Schedules, and Bordereaux
- From Raw Data to Risk Insights: The Role of Extraction in Data-Driven Insurance
- 5 Insurance Documents You Should Be Extracting from Automatically — and How
- Data Routing After Extraction: Where It Goes and Why It Matters
The Landscape: What Data Lives Where in Insurance Operations
Document chaos is consistent across the P&C value chain - but the formats, critical fields, and users vary depending on the workflow. Here’s a snapshot of the ecosystem that your teams battle with:
Submission & Underwriting
Think ACORD apps, broker emails, loss runs, property schedules, and IoT feeds. Key data includes named insured, geolocation, construction class, prior losses, and requested limits - all vital for pricing risk accurately. Used by underwriting teams and triage staff trying to prioritize fast-moving opportunities.
Policy Issuance & Servicing
Once a quote binds, the data journey continues: quote-to-bind emails, endorsements, policy jackets, invoices. These carry premium values, endorsement codes, effective dates, and commission details - used by policy admin teams and back-office broker ops to ensure clean issuance and accurate servicing.
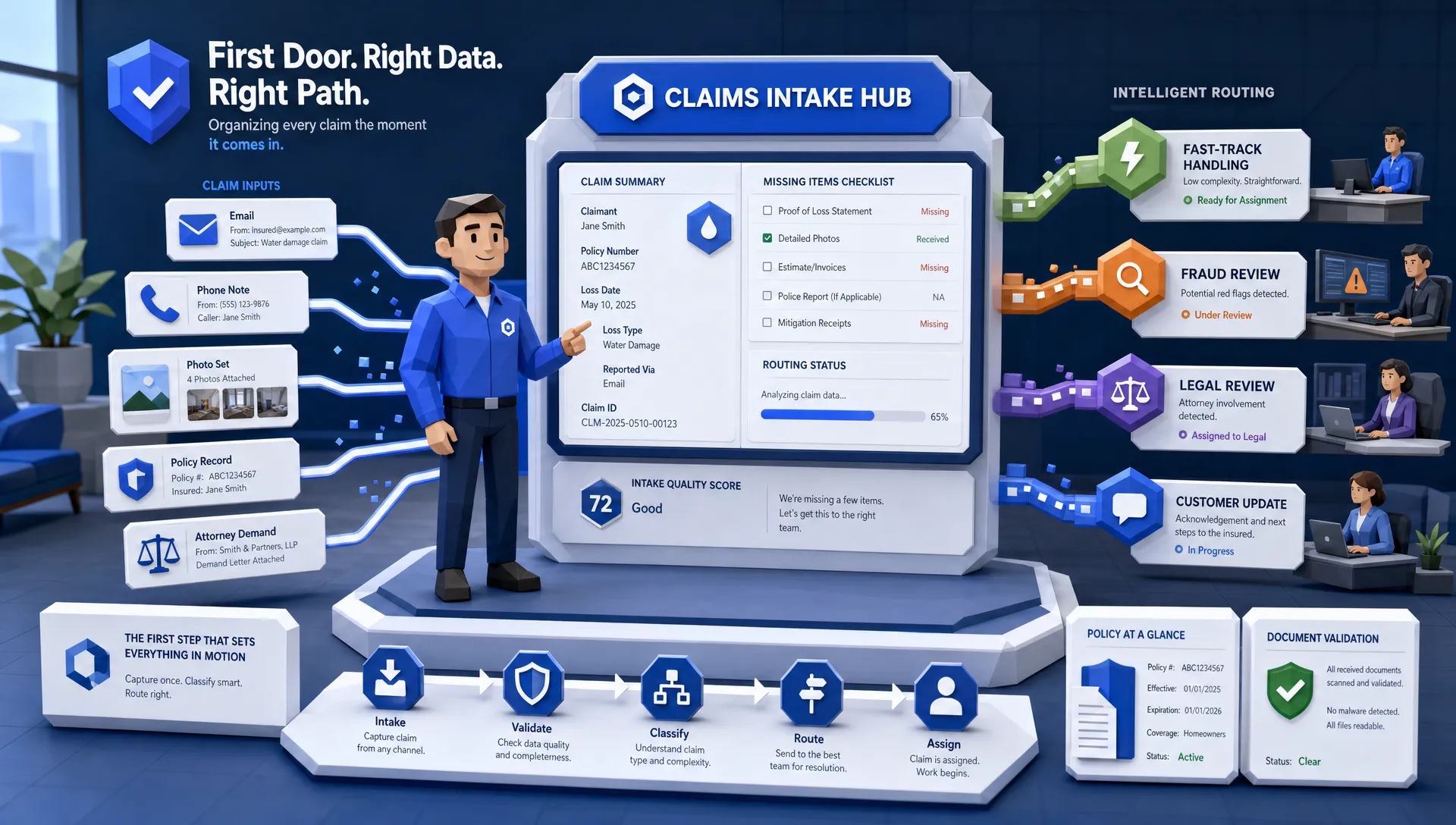
Claims (From FNOL to Resolution)
The FNOL comes in. Then medical bills. Then repair estimates. Then scanned police reports. Every one of these holds critical datapoints: date and cause of loss, reserve amounts, CPT/ICD codes, repair costs, and liability markers. Claims adjusters and TPAs need them structured fast - not two days later.
Accounting & Reinsurance
Reinsurance accountants wrestle with bordereaux, treaty wordings, facultative slips, and modeling outputs. They need ceded premium amounts, coverage percentages, claim recoverables - and the ability to tie all this to the correct treaty layers. Often under deadline from multiple reinsurers simultaneously.
Compliance & Reporting
From sanction checks to ESG disclosures to audit-ready filings, compliance and risk teams spend hours pulling data out of policy docs and spreadsheets to populate regulatory templates.
In all these workflows, the data exists - but it’s locked inside a file. And until it’s extracted, standardized, and routed, it’s just delay.
The Human Cost of Manual Data Extraction
Data extraction today still relies far too much on humans doing the work that technology should own. Underwriting assistants split PDFs and key ACORDs. Claims adjusters copy line items from scanned repair bills. Reinsurance teams retype bordereaux line by line. Compliance analysts review policy docs manually for sanctions clauses.
According to Inaza client benchmarks and industry research:
- Underwriting ops teams spend up to 40% of their time rekeying data.
- Claims adjusters spend 2–3 hours per claim just handling documents.
- Submission clearance teams regularly take 24–48 hours to prepare broker packages for actual underwriting review.
Even with offshore processing and spreadsheet macros, error rates stay high - and the work never scales cleanly during CAT events, seasonal renewals, or large book transfers.
Worse, this effort goes unmeasured. It’s hidden inside "business as usual" workflows - but the cost is very real. It shows up in delayed quotes, SLA breaches, reputational strain with brokers, and burnout on the ops floor.
Why Rigid OCR and Templates Fail
Many insurers have already tried automation - or at least what passed for it five years ago. But static OCR templates break whenever a broker changes layout. RPA tools can’t handle conditional fields or inconsistent formats. And most general-purpose document platforms weren't built with insurance use cases in mind.
The result is automation that only works for one form, one time, under perfect conditions.
What insurers need now is intelligent document processing that adapts - one that understands insurance documents contextually, extracts with confidence, and scales without constant retraining.
What True AI-Powered Data Extraction Looks Like
Inaza’s approach to data extraction uses modern AI to mirror - and outperform - what your best ops and underwriting staff do today.
- Ingest & Classify: Emails, PDFs, scans, Excel, and images are automatically ingested and their document types detected. No manual sorting or tagging needed.
- OCR & Layout Analysis: Vision models detect tables, handwritten notes, checkboxes, page structure - whether it’s a scanned ACORD, a medical bill, or a loss schedule with 300 rows.
- Entity Extraction: Using LLMs trained on insurance ontologies, the system recognizes industry-specific fields: VINs, deductible amounts, CPT codes, limit terms, ICD-10, and more.
- Validation & Rules Enforcement: The data is validated against core systems or business rules - flagging anomalies, missing fields, or mismatches before they go downstream.
- Structured Output Delivery: Clean, confidence-scored data is delivered in JSON, XML, or CSV - ready to flow into your policy systems, claims platforms, or data lake.
This is how leading insurers are enabling straight-through processing, not just partial automation.
Where the Impact Hits First
Underwriting teams report quoting time reduced by 30–50% when submission docs are pre-parsed. Claims groups using structured FNOL data have pushed over 80% of cases into automated adjudication flows. MGAs processing broker submissions through Inaza’s intake see a 60% reduction in human touchpoints per file.
Reinsurers using automated bordereaux extraction eliminate two full days of manual ingestion per month, per treaty. Compliance teams spend less time on audits and filings - because they can search and extract from documents, not read every page.
And across all functions, staff report less burnout and more time spent on judgement calls, not busywork.
What Makes Inaza Different
Inaza’s data extraction engine is designed specifically for the complexity of insurance documentation - from high-volume claims intake to treaty-level ceded premium matching.
Here’s what makes it stand out:
- Multimodal Parsing: Extracts structured data from PDFs, Excel, Word docs, scans, and images - not just text but tables, diagrams, and contextual clues.
- Insurance-Native Intelligence: Pre-trained on ACORD forms, loss runs, quote emails, medical reports, bordereaux - no templates needed, and models continuously learn.
- Real-Time, Explainable APIs: Every field comes with a confidence score, traceable to its origin in the document. Ideal for audits, compliance, and system trust.
- Plug-and-Play Architecture: Integrates easily with Guidewire, Duck Creek, Sapiens, Salesforce, Snowflake, or wherever your data needs to go.
You don’t need to rebuild your tech stack. You just need to stop wasting time rekeying the same data that’s already in your hands.
If You Take One Thing From This
Your teams are already doing data extraction - it’s just manual, slow, expensive, and error-prone. AI-based data extraction doesn’t replace the work. It replaces the wasted time and makes the data usable across underwriting, claims, reinsurance, compliance, and beyond.
Whether you start with loss runs, FNOLs, or bordereaux - start. The return comes fast. The tech is ready. And the pressure to move isn’t going away.
Ready to turn unstructured data into competitive advantage? Talk to Inaza today.